
스택, 큐, 덱 정리 (Stack / Queue / Deque)
🦥 스택 (Stack)
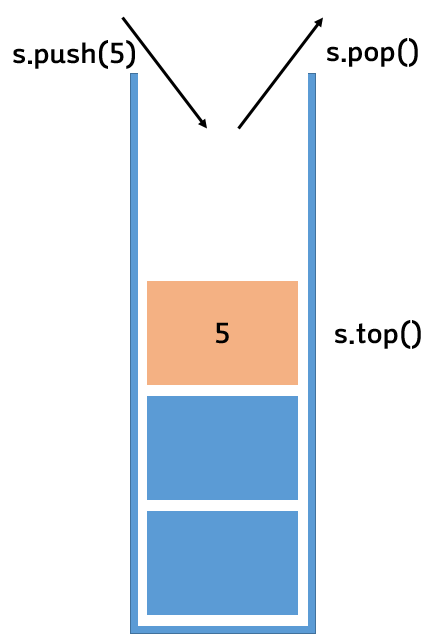
🌴 특징
- LIFO (Last In First Out) 구조 : 한 쪽 끝에서만 자료를 넣고 뺄 수 있는 구조. 스택에 데이터를 push하면 top 원소가 삽입되고, pop하면 top 데이터가 삭제된다. (쌓여있는 접시와 같은 구조)
- 맨 위 요소에만 접근할 수 있다.
- 자료가 없을 때 pop하는 오류를 stack underflow라 한다. 그리고 스택의 크기 이상의 자료를 push 하려고 할 때의 오류는 stack overflow라고 한다.
🌴 시간 복잡도
- 원소를 삽입/삭제하는 경우 : O(1)
- 탐색
- 탐색하는 것은 stack의 구조와 맞지 않다. 굳이 한다면 O(n)
- top 원소 탐색 : O(1)
🌴 장점
- 데이터의 삽입과 삭제가 빠름 : push, pop 모두 O(1)
- top 원소 접근이 빠르다 O(1)
- 히스토리 역추적하기 좋은 구조다.
🌴 단점
- 탐색(접근)이 어려움 : 탐색을 하려면 원소를 하나씩 pop하면서 해야한다. 애초에 stack에서 index 접근이 불가능하다는 것이 탐색을 하려는 목적으로 쓰는 자료구조가 아니라는 것이다.
- 중간 데이터를 삽입, 삭제, 탐색해야 할 경우 매우 비효율적이다.
🌴 언제 사용할까
- 재귀 알고리즘에서 유용하게 사용
- 역추적을 해야할 때 (ex. 문서 작업 시 실행 취소)
- 중간 원소를 삽입/삭제/탐색하지 않을 때
🦥 큐 (Queue)
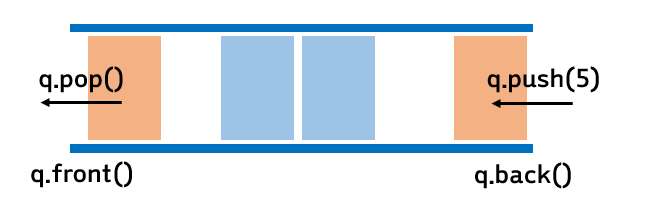
🌴 특징
- FIFO(First-In-First-Out) 구조 : 먼저 넣은 데이터가 먼저 나오는 구조
- queue의 사전적 정의는 (무엇을 기다리는 사람, 자동차 등의) 줄. 기다리는 줄에서 먼저 선 사람이 먼저 나갈 수 있는 것처럼, 먼저 들어간 데이터가 먼저 나가는 것에서 붙여진 이름이다.
- 데이터를
front로 삽입하고,back에서 삭제한다.
🌴 시간 복잡도
- 원소를 삽입/삭제하는 경우 : O(1)
- 탐색하는 것은 queue의 구조와 맞지 않다. 굳이 한다면 O(n)
🌴 장점
- 데이터의 삽입/삭제가 빠르다 O(1)
- 입력된 순서대로 데이터를 처리해야 할 때 유리하다
🌴 단점
- queue 중간에 위치한 데이터의 접근이 어렵다
참고
- 선형 큐 : 1) Front는 고정, Back을 이동하면서 데이터를 삭제하는 경우: 데이터를 제거했을 때, 나머지 데이터를 한 칸씩 다 옮겨야 함. 2) 둘 다 이동하면서 삽입, 삭제를 할 경우 : 배열의 끝에 저장되어 있는 상황되면, Back을 더 이상 이동시킬 수 없어서 overflow 발생.
- 순환 큐(환형 큐) : 선형 큐를 보완하기 위한 방식. front가 큐의 끝에 닿으면 큐의 맨 앞으로 자료를 보내서 원형으로 연결.
🌴 언제 사용할까
- 데이터를 입력된 순서대로 처리해야 할 때
- BFS (너비 우선 탐색) 구현할 때
🦥 덱 (Deque)
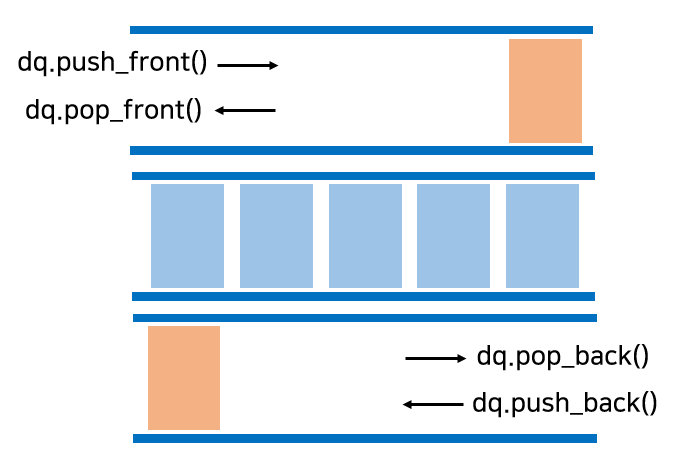
🌴 특징
- queue는 front에서만 삭제하고, end에서만 삽입하는데, deque는 front와 end에서 삭제와 삽입이 모두 가능하다.
- deque의 양 끝을 가리키는 포인터 2개를 갖는다. vector는 연속된 메모리 기반의 컨테이너
🌴 시간 복잡도
- 원소를 삽입/삭제하는 경우 (앞/뒤에) : O(1)
- 탐색 : O(1) (index 접근)
🌴 장점
- 데이터의 삽입과 삭제가 빠름 : 불연속적으로 메모리가 할당되어, 삽입과 삭제 시 기존 원소를 복사한다. 이때 새로운 메모리 공간을 만들 필요가 없어서 속도가 빠르다.
- 크기가 가변적 : 새로운 원소를 삽입/삭제할 때에, 메모리 공간이 자동으로 확장/축소된다.
- 인덱스 접근 가능 : 인덱스를 통해 임의의 원소에 접근(random access)이 가능하다.
🌴 단점
- 최소 메모리 공간이 큼 : 하나의 원소만 가진 deque도 큰 메모리 공간을 차지한다.
- deque의 중간에서의 삽입과 삭제가 어렵다.
- 구현이 어렵다.
🌴 언제 사용할까
- 앞과 뒤에서 삽입, 삭제가 자주 일어나는 경우
- 데이터의 개수가 가변적일 경우
- 데이터 검색을 거의 하지 않을 경우 (랜덤 요소에 접근해야할 때)
Leave a comment