
[Machine Learning] json으로 저장한 dlib 랜드마크 데이터 그래프 가시화
종합 설계 프로젝트 기록
저번 포스트에서 ‘left.json’, ‘right.json’으로 왼쪽 저작 영상, 오른쪽 저작 영상을 따로 저장했다. 오늘은 저장한 데이터를 가시화하여 분석하기 위해 아래와 같은 dataframe을 만들어서 저장했다.
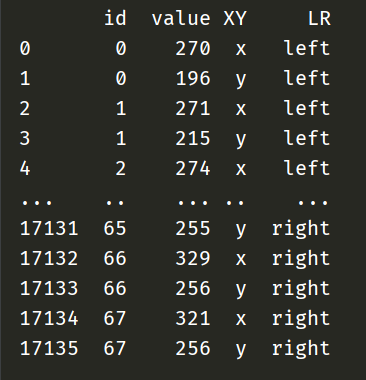
처음에는 dataframe으로 하지 않고 중첩 리스트로 만들었다. count행 68열로 만들었는데, 시각화를 하기 위해서 그림을 그리려면 dataframe을 활용해야 했고, dataframe에서 column index로 x, y축을 정하기 때문에 위와 같은 형태로 수정했다. 처음에 리스트로 구현해서 가시화 한 것이 아래 그림이다.
dataframe으로 변경하고, column명도 추가해주고 나서 시각화시켜보았다. 변화를 수평 방향으로 나타낼 지, 수직 방향으로 나타낼 지 조금 고민했는데, box plot으로 자료가 흩어져 있는 정도를 보기 위해서는 x축을 landmark 번호로 하고, y축을 그 값으로 하는 것이 최적일 것이라고 판단했다. 자료가 흩어져 있는 정도를 보려고 한 이유는 자료가 흩어져 있다라고 하는 것은 어느 정도 움직임이 큰 것이라고 판단할 수 있다고 생각했기 때문이다.
sns.boxplot(x="id", y="value", hue="LR", data=landmark_df_x)
# sns.swarmplot(x="id", y="value", hue="LR", data=landmark_df_x, size = 1)
plt.xlabel('face landmarks')
plt.ylabel('coordinates')
plt.title('Landmarks analysis - X')
plt.legend(loc='upper right')
plt.show()
boxplot을 출력한 결과는 아래와 같았다.
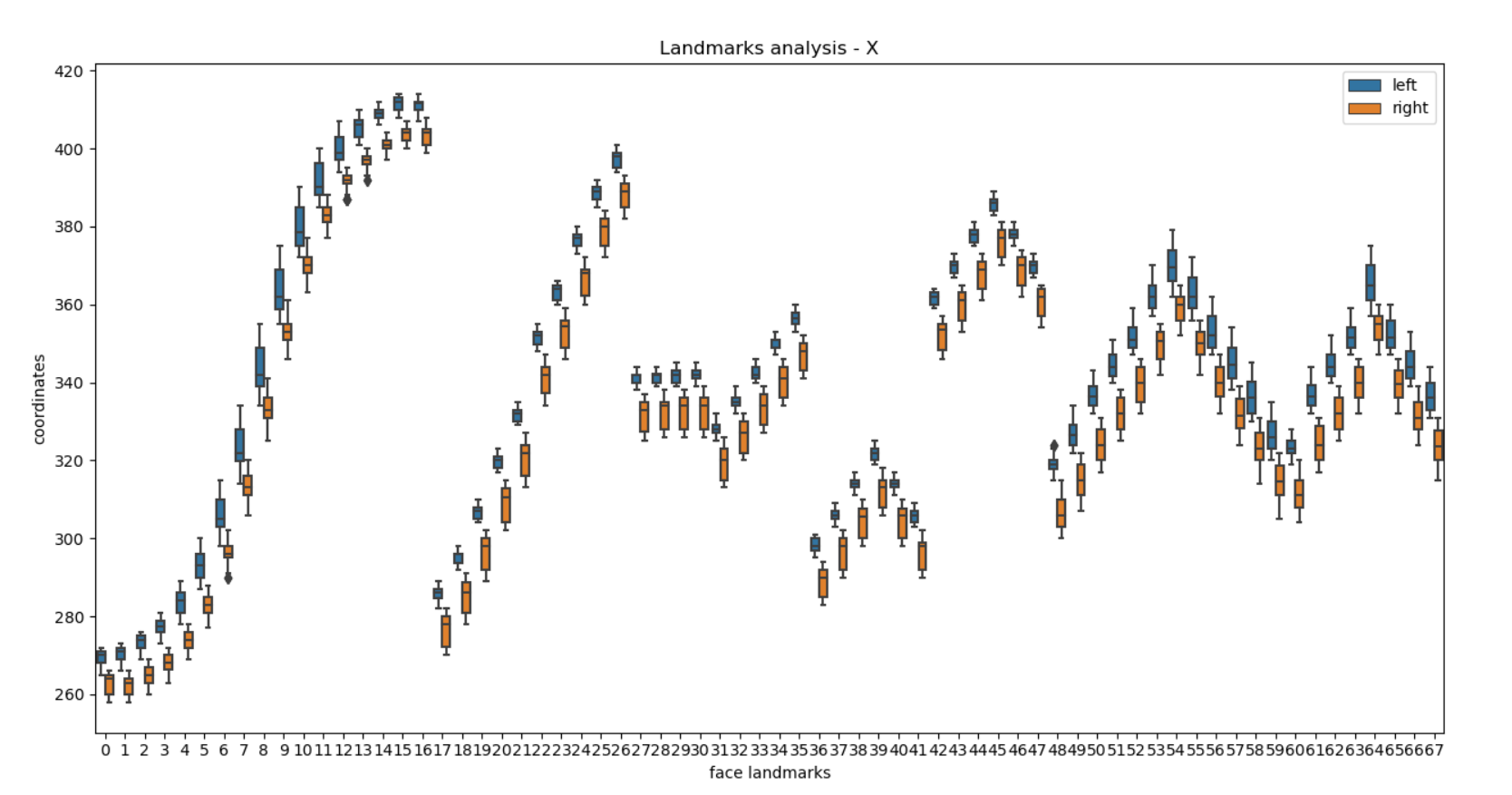
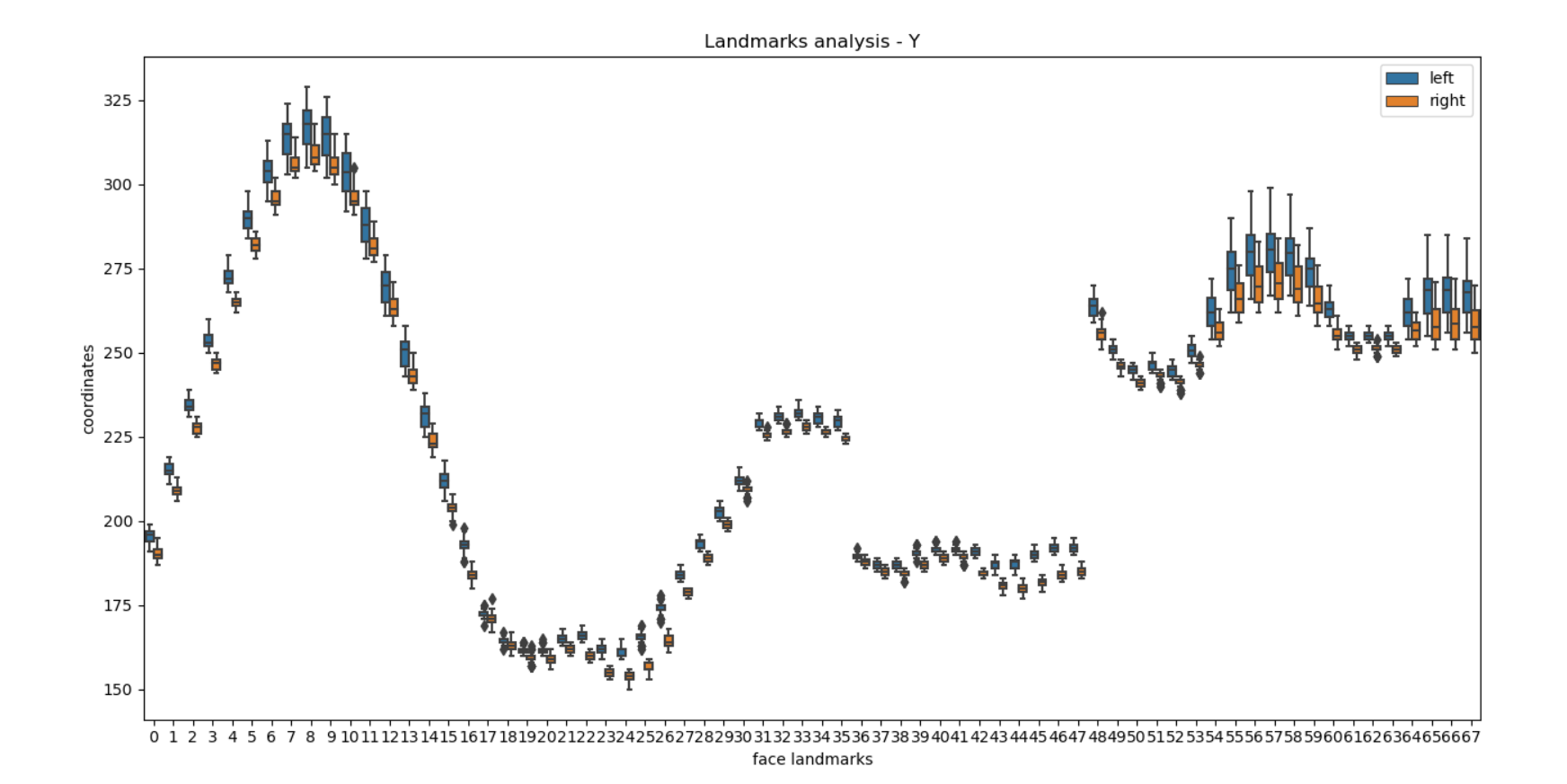
아직 정확하게 분석해보지는 않았지만, 뭔가 딱 봤을 때 x축 방향 보다는 y축 방향의 좌표가 흩어져 있는 정도의 차이가 크고, 내가 예상했던 하관쪽에서의 움직임이 발생한 것을 볼 수 있었다.

5-12(턱 쪽), 50~60(입) 쪽 변화가 확연하게 큰게 보인다. 근데 49~67번, 즉 입쪽에서 왼쪽 부분의 변화가 적어서 불균형하게 씹는 것으로 예상된다. 몇 개의 논문에서는 이렇게 점 하나하나의 좌표값의 변화 말고 그룹핑한 변화로 판단하기도 한다.
Leave a comment